
Moving from a Globus to an HTCondor Compute Element

When we switched Tusker from PBS to Slurm, we knew that we would have issues with the grid software. With PBS, Globus would use the scheduler event generator to efficiently watch for state changes in jobs, ie idle -> running, running -> completed.. But Globus does not have a scheduler event generator for Slurm, therefore it must query each job every few seconds in order to retrieve the current status. This caused a tremendous load on the scheduler, and on the machine.
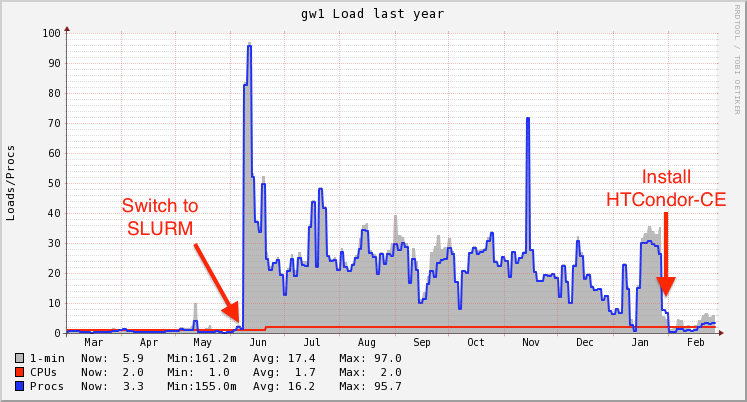 |
| Load graph on the gatekeeper |
The HTCondor-CE also provides much better transparency to aid in administration. For example, there is no single command in Globus to view the status of the jobs. In the HTCondor-CE, there is, condor_ce_q. This command will tell you exactly what jobs the CE is monitoring, and what it believes is their job status. Or if you want to know which jobs are currently transferring input files, they will have the < or > symbols for incoming or outgoing, respectively, in their job state column.
The HTCondor-CE uses the same authentication and authorization methods as Globus. You still need a certificate, and you still need to be part of a VO. The job submission file looks a little different, instead of gt5 as your grid resource, it is condor:
Loading ....
Improvements for the future
The HTCondor-CE could be improved. For example, each real job has 2 entries in the condor_ce_q output. This is due to the job routing from the incoming job to the scheduler specific job. The condor_ce_q command could be improved to show linking between the 2 jobs, similar to the dag output of the condor_q command.
The job submission file is removed after a successful or unsuccessful submission to the local batch system (Slurm). This can make debugging very difficult if the job submission fails for any reason. Further, the gatekeeper doesn't propagate stdout / stderr of the submission command into the logs.
Final Thoughts
The initial impressions of the HTCondor-CE have been very good. Since installing the new CE, we have had ~100,000 production jobs run through the gatekeeper from many different users.
And now for the obligatory accounting graphs:
And now for the obligatory accounting graphs:
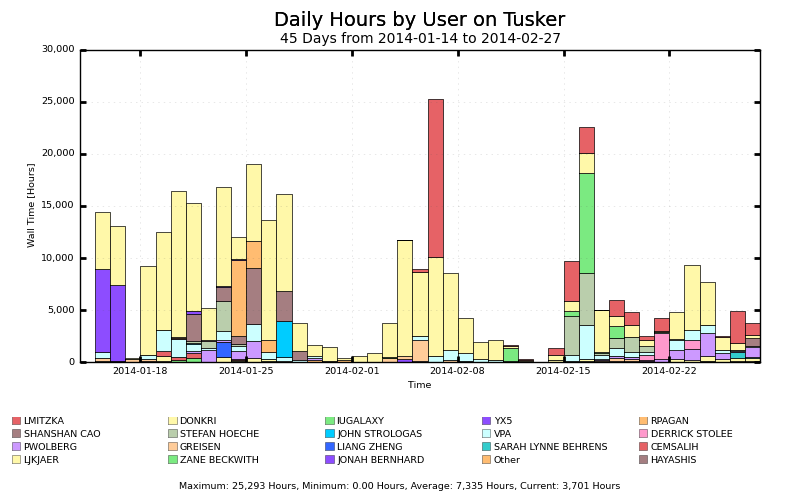 |
| Usage of Tusker as reported by GlideinWMS probes. |
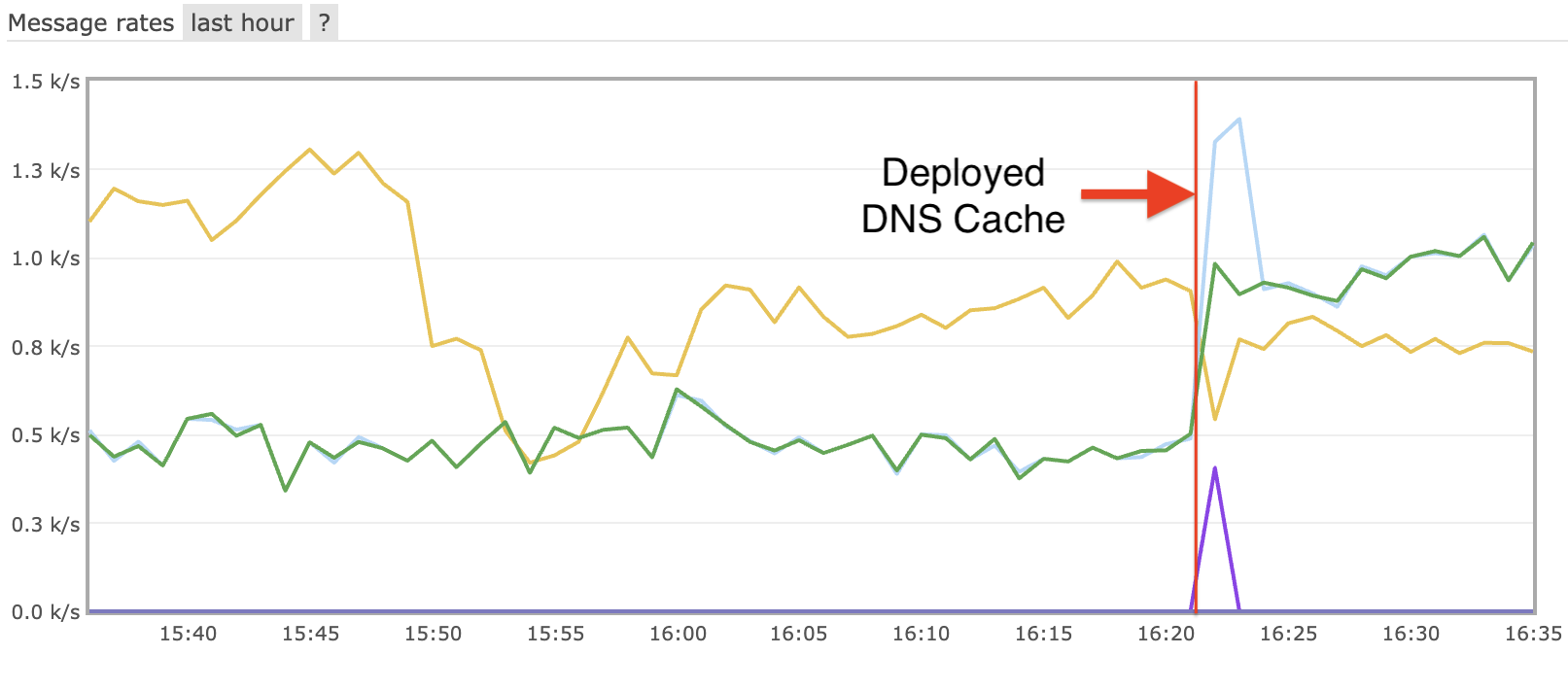
 |
| Wall Hours by VO on Tusker since the transition to the HTCondor-CE |
Leave a comment